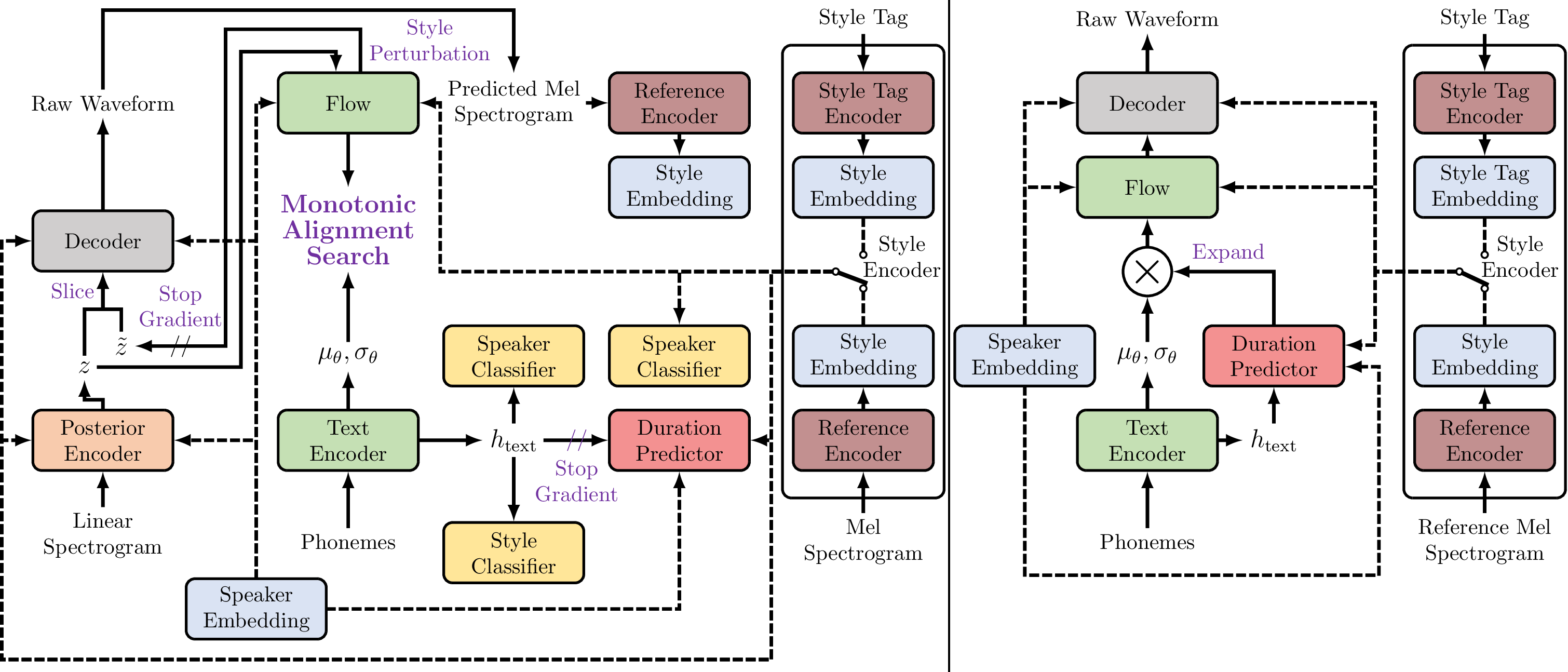
Abstract: Since previous emotional TTS models are based on a two-stage pipeline or additional labels, their training process is complex and requires a high labeling cost. To deal with this problem, this paper presents E3-VITS, an end-to-end emotional TTS model that addresses the limitations of existing models. E3-VITS synthesizes high-quality speeches for multi-speaker conditions, supports both reference speech and textual description-based emotional speech synthesis, and enables cross-speaker emotion transfer with a disjoint dataset. To implement E3-VITS, we propose batch-permuted style perturbation, which generates audio samples with unpaired emotion to increase the quality of cross-speaker emotion transfer. Results show that E3-VITS outperforms the baseline model in terms of naturalness, speaker and emotion similarity, and inference speed.
| Emotional categories: NEUTRAL | |
|---|---|
Style tag : #지문(normally) |
Style tag : #지문(normally) |
| Emotional categories: ANGRY | |
|---|---|
Style tag : #짜증난듯(annoyed) |
Style tag : #화가난듯(seem angry) |
| Emotional categories: JOY | |
Style tag : #행복한듯(happy) |
Style tag : #반가운듯(welcoming) |
| Emotional categories: SAD | |
Style tag : #억울한듯(feeling unfair) |
Style tag : #울먹이듯(about to cry) |
blue tags
are tags in the dataset, and thered tags
are newly created tags, which are not in the dataset.| No. | Seen | Unseen | ||||
|---|---|---|---|---|---|---|
| 1 | #기진맥진한듯 (exhausted) |
#덤덤하게 (flat) |
#힘없이 (weakly) |
#큰소리로 (louldy) |
#냉정하게 (coldly) |
#힘없이 (weakly) |
#친절하게 (kindly) |
#다그치긋 (urging) |
#정답게 (warmly) |
#기쁜듯 (happy) |
#정색하며 (straight face) |
#활기찬 (lusty) |
|
| 2 | #놀란듯 (surprised) |
#너그러운 (generous) |
#낙담한듯 (disappointed) |
#신기한듯 (interesting) |
#악을쓰듯 (shouting) |
#높은 목소리로 (high-pitched voice) |
#불편한듯 (uncomfortable) |
#수긍하듯 (agreeing) |
#혼란스러운듯 (confused) |
#억울한듯 (feeling unfair) |
#울먹이듯 (about to cry) |
#낮은 목소리로 (low-pitched voice) |
|
| No. | Seen | Unseen | ||||
|---|---|---|---|---|---|---|
| 1 | reference 1 |
reference 2 |
reference 3 |
reference 1 |
reference 2 |
reference 3 |
synthesized 1 |
synthesized 2 |
synthesized 3 |
synthesized 1 |
synthesized 2 |
synthesized 3 |
|